はじめに
皆さんこんにちは,2回生の健太朗(@averak_jp)と申します。以前にKC3の司会を務めさせていただいた者です。
さて,令和元年2月に立命館ダジャレサークル(通称:RDC)が設立されました。RDCではダジャレ判定サービスを提供しており,中でも私はダジャレ判定/評価エンジンの開発を担当しております。
私はこれをDaaS(Dajare as a Service)と呼んでいます。
本記事ではダジャレの判定及び評価アルゴリズムについて紹介しましょう😎
※ 釣りタイトルでごめんな謝意
ダジャレをコンピュータから扱おう
自然言語であるダジャレをコンピュータで扱うには,当然自然言語処理のテクニックが必要になります。昨今の自然言語処理の学習をサポートする記事や書籍では,偉大なアルゴリズムを複数紹介しています。
偉大な自然言語処理アルゴリズムであっても,ダジャレの判定から評価までをend-to-endで行うのは厳しいでしょう。そこでダジャレエンジンを
- 判定エンジン(ダジャレかどうかの判定)
- 評価エンジン(ダジャレを星1〜5でスコア化)
の2つに分けて実装することにしました。
ダジャレ判定
ここで質問です。
ダジャレとは何か?その意味を定式化せよ
この質問は日本人を震え上がらせます。不思議なことに,飲み会でふと出る発言がダジャレかどうかの判断はついても,その具体的な定義は説明できないのです。
定義が曖昧では実装など不可能です。この謎を解くために,Google先生の力を借りることにしましょう。
色々と調べた中では下記記事がとても参考になったので紹介します。
(ベースとなる理論は下記記事に準拠しています)
ざっくりと説明すると,この記事ではダジャレを下記のように定義しています。
カタカナに変換した文字列のtri-gramに重複している要素があれば,元の文字列はダジャレである
この定義を元に,判定エンジンを前処理部→判定部という流れで実装しています。
上記記事では具体的な実装方法も記載されておりますので,自分でダジャレエンジンを作りたいという方は是非試してください。ダジャレを判定するAIといっても,ルールベースで実装しているので簡単なプログラミングができれば理解は容易いでしょう。
本記事の残りでは,上記記事における基本的なアルゴリズムと,それでは不十分と考えた点を補う仕組みについて紹介します。
前処理部
前述したダジャレの定義は,ダジャレは音が重要であるという発想からヒントを得たようです。
例えば日本語において,促音「ッ」や長音「ー」は発音しなかったり,「到底(/t o u t e i/)」は「とーてー(/t o: t e:/)」と変化するなど,文字通りに発音するとは限らないのです。このような現象を調音音声学では下記のように説明しています。
- 調音結合
- 母音の無声化
- 母音の調音化
高精度な判定アルゴリズムを作るためには,この現象を前処理部で再現する必要があります。
他にも一般的な自然言語処理と同様に「記号等のノイズ除去」を行い,結果を後続の判定部に渡します。
判定部
ダジャレの判定にはn-gramを利用します。
n=3のとき,「スカラデスカラ」→「スカラ,カラデ,ラデス,デスカ,スカラ」
n=4のとき,「スカラデスカラ」→「スカラデ,カラデス,ラデスカ,デスカラ」
tri-gramの重複要素を探すだけでは,どうしても取りこぼすケースが出てきます。本タイトルの「Slacaですから(スカラ=スカラ)」のような単純なパターンでは問題ないですが,「ダジャレを言うのは誰じゃ(ダジャレ≠ダレジャ)」のように文字の入れ替えがあるケースには対応できません。
そこでfour-gramの出番です。4文字ずつの分割と曖昧一致のアイディアが文字の入れ替えを吸収します。
ここでいう文字列の曖昧一致とは,完全一致を下記のように拡張したものを指します。
- 文字を並べ替えたときに完全一致するか(例:「あいう」と「あうい」)
- 母音が完全一致するか(例:「あいう」と「かきく」→ 母音「aiu」で一致)
- 子音が完全一致するか(例:「かきく」と「くけこ」→ 子音「kkk」で一致)
(一つでも当てはまれば曖昧一致している)
上記の曖昧一致のアイディアを元に,下記のようにダジャレ判定条件を再定義しましょう。
- 3文字以上完全一致
- 2文字以上完全一致&母音完全一致
- 2文字以上完全一致&子音完全一致
- 2文字以上の形態素が一致(例:「臭いサイ」)
このようにn-gramの比較に曖昧さを持たせることで,より多くのダジャレをダジャレだと判定できるようになるのです。
しかし,判定されやすさを高めた代償に非ダジャレをダジャレであると誤判定するケースが増えることでしょう。
ダジャレであると判定するアルゴリズムを強化するのと同等に,ダジャレでないと判定するアルゴリズムも必要です。ここでは解説しないので,興味があればソースコードを読んでください。(他にも2文字一致「臭いサイ」対応するメソッドなども用意しています)
ダジャレ評価
先ほどのダジャレ判定にはルールベースAIを用いましたね。一方でダジャレの評価は深層学習の力に頼ります。ここで下記のような疑問を抱いた方もいるでしょう。
なぜルールベースで統一しないのか?
答えは単純。ルールがわからないからです。良いダジャレの漠たるイメージや評価軸は皆さんの頭の中にあることでしょう。しかし,それらを明文化するのは容易ではありません。
ダジャレの評価は難しい
例えば下記のダジャレにランキングをつけるとします。
- 片田舎の固い仲
- 臭いサイ
- スロットで金すろーと
1と2を比較すると,ほとんどの人は1の方が面白いと判断しますよね。なぜでしょう?被った文字数?それとも選出された単語そのものの面白さでしょうか?この程度であれば工夫次第でコンピュータでも判断できそうな気がします。
では1と3を比較してください。この場合,どちらが優れているとは決め難いのではないでしょうか。特に3のダジャレは特殊で,シチュエーションによって面白さが変動するのです。学校や職場ではしらけるかも知れませんが,パチンコ店で聞くと面白さは格段に跳ね上がりますよね。
このようにダジャレの評価ロジックは,判定に比べ明文化しにくいと私は考えています。そこで,ルールの抽出すらもコンピュータに委ねる深層学習に至ったのです。
深層学習でスコア化しよう
数ある深層学習アルゴリズムの中でも,今回はcharacter-level CNNを採用しました。
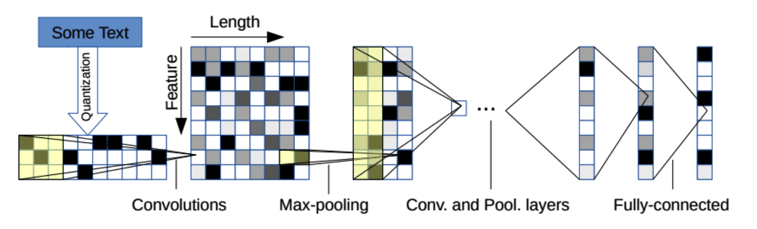

通常の自然言語処理が単語レベルであるのに対し,文字レベルで処理することでダジャレは音が重要であるという前提に準拠した形です。
結果は…ほぼ乱数ですw
6万件のダジャレデータを学習してもこの結果です。(教師データがでーたらめだったのかな?)
良いアイディアがある方,プルリクお待ちしております💪
参考文献
おまけ
いかがでしたか?以上がDaaSの仕組みになります。
私は音響側の人間(?)なので脳死機械学習を嫌っています。悩んだ挙句ダジャレの評価に深層学習を取り入れる決断をしましたが,そのアプローチが有効なのかは懐疑的です。(結果失敗してますしね)
歴も知識も浅い私ですが,データ分析ではドメインの理解が常に重要であると考えています。DaaS開発において,ダジャレの面白さは発言するシチュエーションや前後の文脈にも依存すると結論づけました。しかし,用意されたテキストボックスに文字列を入力して遊ぶというサービスの性質上,マルチモーダル的な分析はおそらく不可能なんですよね。。
説明変数をテキストのみに絞ったとき,どのような手法が有用でしょうか?まだまだ考えることはいっぱいです。そもそもダジャレを数理的に分析する学問ってあるんですかね?
最近はDaaS開発に一旦ピリオドを打って,競馬AI🐎立命の母を開発しています。データ分析は調査が多くて疲れますが,続けているのだからきっと楽しさもあるのでしょう。
最後にDaaSを開発するにあたって印象的だった出来事を呟きたいと思います。暇な方は見てください。
RDC最大の失敗
世の中には好き好んで治安の悪い発言をしたがる人がいるのです。
そんな人がRDCに入会したとある日,Slackチャンネルにて「う○ちがう○ちった」,「ち○こガチンコ勝負」といった低質なテキストが投稿されました。(RDCでは,Slackチャンネルにて投稿したダジャレが会公式ツイッター(@rits_dajare)に共有される)
確かにセンシティブな表現を含むダジャレは面白いのですが,それをツイッターで投稿すると凍結される恐れがあるため歓迎されるものではありません。
そこで私はダジャレ判定エンジンにセンシティブフィルタを追加することにしました。テキストに生殖器スラングや恐喝等のセンシティブタグを付加して弾く仕組みです。
結果は想像に反して,彼ら(私含め)は水を得た魚のようにセンシティブフィルタを通過するギリギリなダジャレを投稿することに喜びを感じるようになりました。
退屈なRDCに新たな遊び方が生まれた!とポジティブな見方をする人もいれば,凍結を恐れ逐一ツイートをする会長のように冷めた目で見る人も出てきます。
センシティブダジャレが爆発的に増えるトリガなんて作らなければ良かった。。そんな失敗談です。
非ダジャレとの格闘
RDCは会外向けのダジャレ判定サービスも公開しています。判定したダジャレとその点数を自身のツイッターにて共有するサービスです。
非会員の中には,このサービスを使って「野球は野球だ」,「あいうあいう」,「日本は今のままではいけないと思います。だからこそ、日本は今のままではいけないと思っている」など,明らかな非ダジャレを投稿する遊びをする人たちがいました。
DaaS黎明期はこのような誤判定をすることが多く,当時退屈していた私は発覚直後に修正&リリースを繰り返していました。修正されていることに気づいた彼らは,重箱の隅をつつくようなダジャレをさらに投稿してきます。
このようないたちごっこがDaaSを劇的に強化しました。
結果としてより高精度なサービスを提供するきっかけを作った彼らですが,最近ではそのような投稿が見受けられなくなり退屈です。